Three methods of retrieving records from CloudKit
We use CloudKit as the backend for Tact. CloudKit stores all of Tact’s data, and we use various methods of retrieving records from CloudKit. There are three methods to do that, but no source that explains what or why they are, or what to consider for each of them. I wish I had those explained to me when I started out. This is the blog post that I wish I had found when starting out with CloudKit 😀
Prerequisites
This post won’t cover CloudKit basics. It assumes you are familiar with the basic concepts, or are able to look them up. Here’s a condensed paragraph that contains many concepts that we will refer back to:
CloudKit data is organised into public, private, and shared databases. Private databases contain a default record zone, and may contain other, custom zones. These custom zones form the basis of sharing in CloudKit (which means making records owned by you accessible to other users whom you share them with). Record is the basic unit of data in CloudKit, similar to a table row in a traditional RDBMS. A record has an owner, record type, record ID (which consists of a zone ID plus system-generated or custom record name string), some system-defined key-value pairs (like “createdAt“, “modifiedBy”), and any custom key-value pairs, where keys are strings and values are data with CloudKit-defined data types. Records may have parent records. Any zone may contain records of any record type. Records in public database aren’t organized in zones, but live straight in the public database. Records that you share in a custom zone of your private database will appear in record zones in the shared database of those users you have shared it with. Parent record sharing permissions automatically apply to its child records.
Did this paragraph make sense? Yes? Good, let’s move on and discuss the three methods. If it didn’t make any sense, try looking up the terms in bold in both Apple docs and external materials to stay with me and not get lost in the term soup.
Oh, and before we retrieve records, we need to store them first. The main way of storing records in CloudKit is CKModifyRecordsOperation. This is a powerful überoperation that handles record creation, modification, and deletion, all in one. You use this operation to store records in CloudKit (after possibly doing other setup work before that, like setting up zones, that we won’t cover here).
After you have stored some records in CloudKit, there are three methods of retrieving them. Let’s finally talk about them.
The three methods
Let’s call them “Query-based”, “Fetch-based” and “Changes-based”, because these are the names of tabs that you see in the CloudKit dashboard which let you perform each of these methods interactively in the UI. If you have a CloudKit app, go to your app’s iCloud dashboard and play along. There are corresponding API-s for all of them that I’ll mention below.
When to use which method? It depends, obviously, on your exact scenario. We use all three in Tact in various places. All of them have their own quirks, which I’ve tried to document below to the best of my knowledge. There is no “better” or “worse” method, just different tradeoffs for each.
I only discuss Operation-based API-s below. There are other flavors of some of these methods available (like fetching one record with a completion handler), but it appears that most of the CloudKit documentation is geared towards operations. I myself also find the operations-based approach to be the clearest to reason about, compose and do things like dependency management and cancellation, so I’ll only discuss Operation-based API-s here.
Query-based retrieving
The API for this is CKQueryOperation. Here’s what it looks like in the web dashboard. (All screenshots are for my own user in the Tact development environment.)
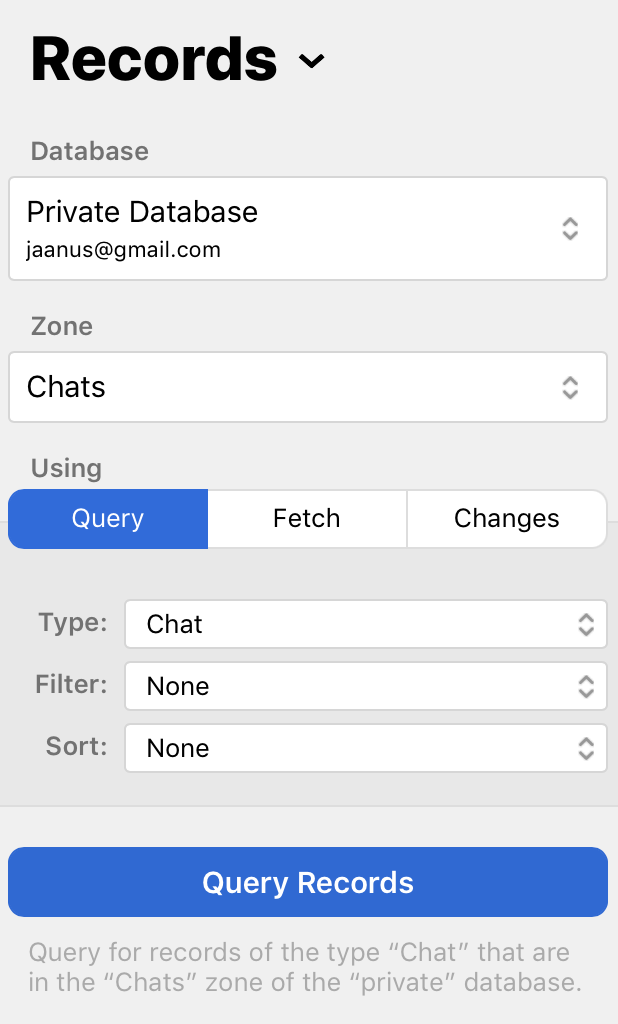
In principle, this is very similar to a traditional database query. You query for exactly one type of record, in exactly one record zone. You can filter your query and the web dashboard has a decent filter editor UI. (This would be the SQL WHERE clause.) You can sort your results. The field(s) that you want to filter by must have the QUERYABLE index set in CloudKit, and the sort field(s) must have the SORTABLE index set. If there is no needed index on a field and you still try to filter or query by it, CloudKit returns a pretty clear error about this in the web UI or to your API call, so do watch those errors during development.
A query may result in many records, more than CloudKit can return in one batch. In this case, it uses cursors that you can pass to subsequent query operations to retrieve the next “page” of results. It works as you would expect. See the API documentation.
Setting desiredKeys on the query limits the fields that the operation returns, and potentially reduces the download size and increases speed. Do query only for the fields that you actually need. If you later need to retrieve the other keys, consider using the fetch-based method discussed below.
This method, as you would expect, returns you the state of the records present in CloudKit at the current moment. It doesn’t tell you about history (or future, for that matter). For one kind of historic view, and more efficient approach to get the current state than just repeated querying for the same things, you can use the changes-based method.
Fetch-based retrieving
Fetch here means “fetch specific records”. The API is CKFetchRecordsOperation. Here’s the web UI.
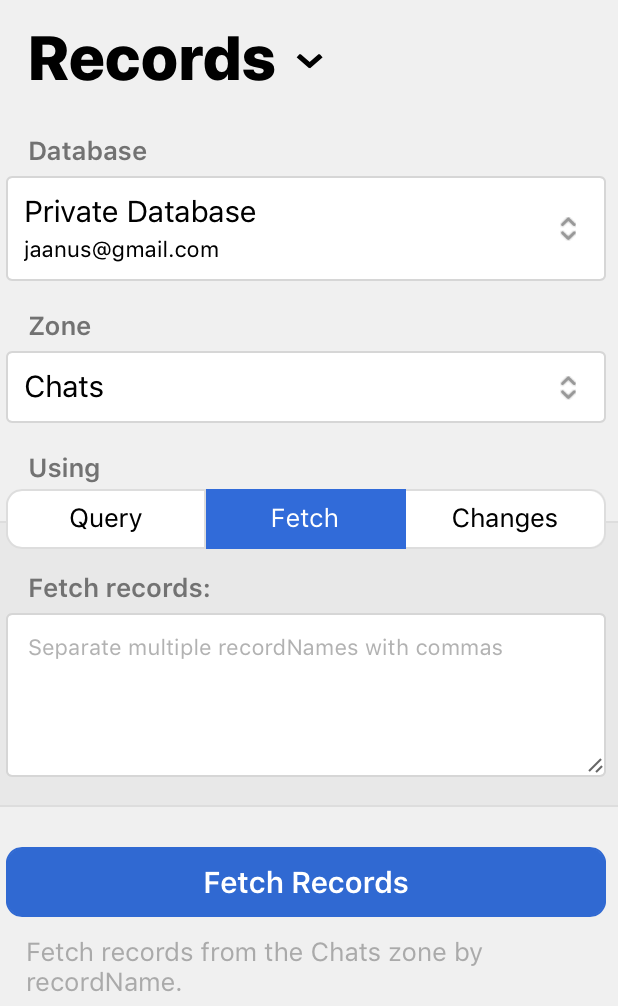
This is also a kind of database query, but there’s no filter or sort. Instead, this means “fetch objects by ID”. (CloudKit calls it recordName, but in my head, it’s object ID.)
You give this API one or more recordNames, and you get back the records. Nothing more, nothing less. Just a few more things to note about it.
Unlike the query-based method, there is no “record type” specifier here. The recordNames can represent records of different types. They still need to live in the same record zone of the same database though (or in the public database without a zone), but you can efficiently fetch multiple records with different types in one CloudKit call, if that happens to be what you need.
The record names are just strings. This API doesn’t say anything about where they come from, or how you store them. They could come from your local cache, previous CKQueryOperation, or any other source.
This is the only API for retrieving records that provides decent progress feedback about the download: perRecordProgressBlock. (The überoperation for saving, CKModifyRecordsOperation, has a similar way for getting feedback about the upload progress.) So if you have a record with one or more large assets among its values, consider doing all the other retrieving without the asset keys to save on the download time and not leave your user hanging for a long time without any feedback. If you actually then need those assets and want to provide feedback as the download happens, use this method, include the asset keys, and use the progress block for providing feedback to the user as the download happens.
Changes-based retrieving
The previous two methods were kind of similar: retrieve some records from the current state of the database according to a specific input (query or record names). Changes-based retrieving is an entirely different beast. Instead of a query, I think of it as “stream of events”, where the events are “add record”, “modify record”, “delete record” (or equivalent zone modifications if you retrieve database changes). This method lets you get a playback of these events over a longer or shorter period of time.
The two API-s for this are CK fetch record zone changes operation and its cousin CK fetch database changes operation. (For brevity, I will refer to them below as CKFRZCO and CKFDCO. See-Kay-Ferzco and See-Kay-Fedco. Just rolling off your tongue.)
On the reference page of CKFDCO, Apple has one of the most useful bits of CloudKit documentation, hidden in the obscurity of documenting one specific operation, that describes the pattern for using these API-s together to most efficiently fetch changes of your app’s data in CloudKit.
When your app launches for the first time, use this operation to fetch all the database’s changes. Cache the results on-device and use CKDatabaseSubscription to subscribe to future changes. Fetch those changes on receipt of the push notifications the subscription generates. It’s not necessary to perform a fetch each time your app launches, or to schedule fetches at regular intervals.
The operation calls recordZoneWithIDChangedBlock for each zone that contains record changes. It also calls it for new and modified record zones. Store the IDs that CloudKit provides to this callback. Use those IDs with CKFRZCO to fetch the corresponding changes. There are similar callbacks for deleted and purged record zones.
There is also a more detailed code example on the same page on how to set this up.
Armed with this knowledge, we can start exploring the relevant parts of the web dashboard. Let’s move away from the Records UI for a moment, to see how we fetch list of record zones. Here is the initial state.

This would simply fetch you the current list of zones in the indicated database, as you can yourself do with CKFetchRecordZonesOperation. In private database, you sort of know what the zones are based on your app’s architecture, so it’s not that interesting. It’s much more interesting in the shared database, where the list of zones changes over time based on what other users have shared records with you. You would possibly see several zones with a similar name, but different owner ID.
Let’s check the checkbox. Here’s how it looks now.
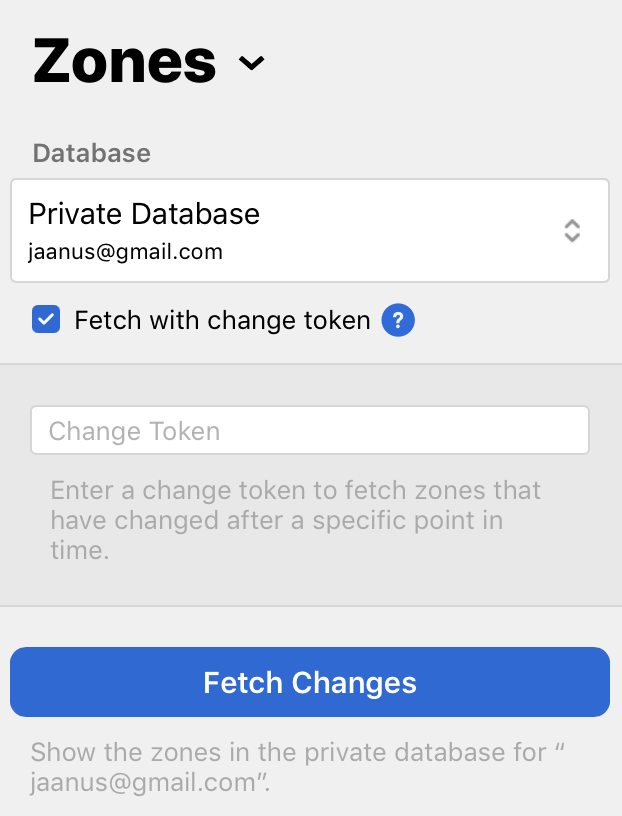
Looks similar, but does a very different thing. Instead of current list of zones, this would give you a historic record of all zone changes since the point in time represented by the database change token that you enter here. (I am actually not sure where to get this token for the web UI, and how to interchange the tokens used by the web UI, and the binary tokens that you manage in your code. Just haven’t needed to do it. They are definitely the same tokens, though, and you can supposedly use the same token with both the web frontend and the API.) The API equivalent for this is the already mentioned CKFDCO.
There’s more nuance to working with database changes which I’ll not cover in this post. Fow now, just know that one of the outcomes of this operation is that you get a list of changed zones, and then proceed to retrieve the changes for all of them. You do that with CKFRZCO. Here’s how it is on the web side.

So what this does: a zone change token represents one point in time. You give this API call a token, and you get a playback of events and records beginning at the time point represented by that token, and ending at “now”. You can also call it without a token, in which case the beginning time point is “ancient history”, “everything” or whatever you want to call it. Ending time point is always “now”.
Besides getting the events, this API call also gives you a new token, representing the “now” time point. You store this token and use it in future calls to the same API, to get the list of changes between “now-now” and “future-now”. (I think these should be official technical terms.)
It all sounds very good and powerful, and it is. You get a list of all changes across all record types, without having to know much else in advance. You can then ingest and process those changes to have an up-to-date local view of the record zone state. You don’t have to do multiple queries, mess around with cursors, predicates and who knows what else. What’s not to like?
Three things, two of which are really one thing.
First, pay attention to the order of the events, and think about how things should actually be ordered for your app purposes. In theory, events should be returned to you in the same order as they happened. I saw behavior with Tact, though, where I created a chat, and then posted a message to it (having the chat as parent record of the message). When I later retrieved the zone changes, I received the “message” event before the “chat” event. I’m not saying this is because the CloudKit API is returning results in the wrong order—it could very well have been because I myself saved the records to CloudKit in the “wrong” order, or whatever else. In any case, I find it best to be defensive and make the least assumptions possible. In Tact case, I find it to be resilient and defensive (and the data model affords doing that) to first collect all the received events from CKFRZCO into a local buffer, and then apply them based on the record type - first, record type A, then record type B (which has records of type A set as parent), and so on. I wish I or someone did more experiments on this, and/or Apple docs provided more details about the event ordering guarantees.
Secondly, and more seriously. This API can be slow. Like, minutes slow. I wish I was joking. This is the only CloudKit API where I’ve encountered speed being a serious issue. Everything else responds in reasonable time and you can predict the performance based on the amount of data and records involved. Like, if you do a CKQueryOperation retrieving a large amount of data, of course the download will take a while, and there is a little delay before getting any results, as iCloud goes around its server room and assembles the results for you. But that delay is measured in seconds, not minutes.
CKFRZCO performance in time scales based on the time point represented by the zone change token you give it. If the token represents some recent time, the performance is fast, as you’d expect. There are no or few changes. If there is no token, though, or the token represents some earlier point in time, the performance is not “slightly less fast”, or even “somewhat slow”. It is “so slow it seriously feels broken”. It can be minutes. All of these minutes are spent in silence on the server side before you get any kind of response. I did some experiments with various configurations of CKFRZCO to see if the amount of data has any effect on this. (You can set desiredKeys to inform which fields you wish to have in the results.) Do the fields effect the response time? The answer is “yes, but not by much”. A query for a longer time period with less desiredKeys takes way longer than a query for shorter time period with more desiredKeys. It really is about the time spent on the server side before returning any results.
Thirdly, there is no API on CKFRZCO to say “I don’t care about the history, just give me a fresh token representing now, which I will use for future queries”. When you first start out with a record zone, you don’t have any knowledge about its state, and no way to obtain this knowledge except to do a full history playback. If you wish to use the changes-based retrieving strategy, your only option is to start from the beginning of time to get all the way to “now”.
We’ll see now why the last two quirks together are an especially unfortunate combination.
Bootstrapping CloudKit state on a fresh device with lots of data across a long time period
Using a changes-based strategy with our friends CKFDCO and CKFRZCO works really well and is quite powerful when you have reasonably up-to-date tokens for all the record zones. Imagine, though, that you are starting out on a new device, with lots of historic data accumulated in CloudKit already. (Not a hypothetical scenario. In Tact, we have several years of data by now.) You get a list of zones with CKFDCO (which is always reasonably fast).
How would you bootstrap your changes-based retrieving strategy, so that all future retrieving in these zones happen reasonably fast? Remember, you have no zone server change tokens at this point.
- Do you just fetch all the history with CKFRZCO? This can be insanely slow and is terrible user experience. I tried this with Tact. Don’t do it. It is seriously atrocious if you ever have any meaningful amount of data for any meaningfully long time period.
- Do you just obtain the tokens representing “now” for each record zone, so that you can use them in future retrievals? As I discussed above, there is no API for doing this. I wish there was.
- Do you just not keep historic data in your app at all, so that all retrieving would be for a reasonably recent period, and CKFRZCO would be fast? This has many benefits, sure. Do it if you can. Less data is less pain. In Tact, though, we currently keep all the history. And there’s nothing in CloudKit philosophy or guidance which would say we shouldn’t do that. As far as we can tell, CloudKit is suitable for keeping data over long periods of time, and most of it works well in this case. CKFRZCO is the one notable exception.
So what are you to do in this case? Are you, to use a technical term, “sh*t out ouf luck”? What did I do with Tact?
I invented an approach which feels kind of clunky but seems to work reasonably well for now. On a new device, the first thing I do is run some CKQueryOperations with predicates for a recent time period to get some fresh data. (Since most of the time the user is anyway only interested in fresh data.) After doing this, the app is already interactive, populated with data, and the user can start using it.
I then kick off CKFRZCO-s to play back the history of all zones to get a fresh token. I set the desiredKeys to an empty array, telling the system that I am not interested in any data. This saves a lot on download volume. (You get the system metadata downloaded anyway, there’s no way to avoid that. But the volume of that is insignificant. The main volume in Tact is assets like files and photos.) I don’t process or store the results downloaded by CKFRZCO in any way. The only thing I am interested in is the final token that I get at the end of each CKFRZCO operation. I save this token and use it going forward to fetch some real results as they arrive.
Running the “blank” CKFRZCO-s is more efficient than downloading all the data, both in terms of initial delay as well as obviously the download side. It still takes time (on the order of minutes), but is reasonably fast. Critically, the user does not have to wait for this to complete to actually start communicating in Tact, since the recent content is already present.
All this works, but I wish I didn’t have to do it and there was a better way. I also suspect the performance of the blank CKFRZCO-s will get worse over time as Tact accumulates more data for a longer, ever-growing time period.
Conclusion
I am reasonably satisfied with working with Tact and CloudKit for the past few years. It mostly works as advertised, and has reasonable performance for Tact purposes. The three methods to retrieve the data all have a role to play in building a well-functioning, usable CloudKit app.
The one notable problem is bootstrapping state on a new device when you wish to use a changes-based retrieval strategy with CKFDCO and CKFRZCO. It feels like an oversight in API design on Apple side to not have a way to retrieve fresh tokens for a record zone without having to play back all the history. If anyone at Apple is reading, I have filed FB9073964 to that effect. I hope that a future CloudKit platform release will have improvements in this area.